はじめに
Udacity DLND、今週は week8。word2vec がテーマ。
週をおうごとによくわからなくなっていくのは、自分だけだろうか。 だんだん、コピペと写経の講座になってしまっている。
リンクが張られてこれ読んでおいてねという感じ。自学自習が重視される。
というわけで、理解を深めるために、試行錯誤してみた。
week8 は、word2vec(skip-gram model) を tensorflow で実装するという内容。 word2vec は、2 層のニューラルネットワークに過ぎないので理解はたやすいのだけれども、 その前処理(SubSumpling)や 高速化のテクニック(Negative Sampling)が意味わからなかった。
この絵で説明する word2vec の解説ページがとてもわかりやすかった。感謝!
演習では、text8 という Wikipedia のデータセットを用いるのだけれども、相変わらず英語で、 日本人の自分にはピンとこない。というわけで、日本語のデータセットを自分で用意して試すことにした。
今回試したフル実装の Jupyter Notebook は以下です。
ツィートをデータセットに用いる
自分の twitter アカウントのツィートをデータセットにもちいることにした。
といっても、元ネタがあって、元ネタはこの記事。
この記事に 自分のツイートを取得する方法が詳しく書いてある。 twitter が csv データを提供してくれるのだ。 ダウンロードすると、tweets.csv というファイルが手に入る。
pandas で読み込んで前処理を加える。 studyplus とか fitbit のログを垂れ流していたので、それらは削除。
raw_data = pd.read_csv('tweets.csv')
text = raw_data['text']
# studyplus の垂れ流しツイートは削除
text = text[text.str.contains("#studyplus") == False]
# fitbit のライフログは削除
text = text[text.str.contains("おはようございます。今日は") == False]
オープンソースの形態素解析エンジンである MeCab をインストールして、 ツイートを単語ごとに分解して保存する。
ここでもさらに文章からゴミを落としていく。以下を参考にした。re.sub を使う。
import Mecab
import re
f_out = open("tweets_wakati.txt", "w" )
for line in text.iteritems():
line = re.sub('https?://[\w/:%#\$&\?\(\)~\.=\+\-…]+','', line[1])
line = re.sub('RT', "", line)
line = re.sub(r'[!-~]', "", line)#半角記号,数字,英字
line = re.sub(r'[︰-@]', "", line)#全角記号
line = re.sub('\n', " ", line)#改行文字
f_out.write(m.parse(line))
f_out.close()
これで tweet データセットがてにはいった。
Word2Vec を Tensorflow で実装
Word2Vec を tensorflow で実装!といっても課題をコピペしただけなので、省略!!
元の課題のコードを見てください。
可視化
こうなりました。自分を構成している概念が可視化されて面白い。
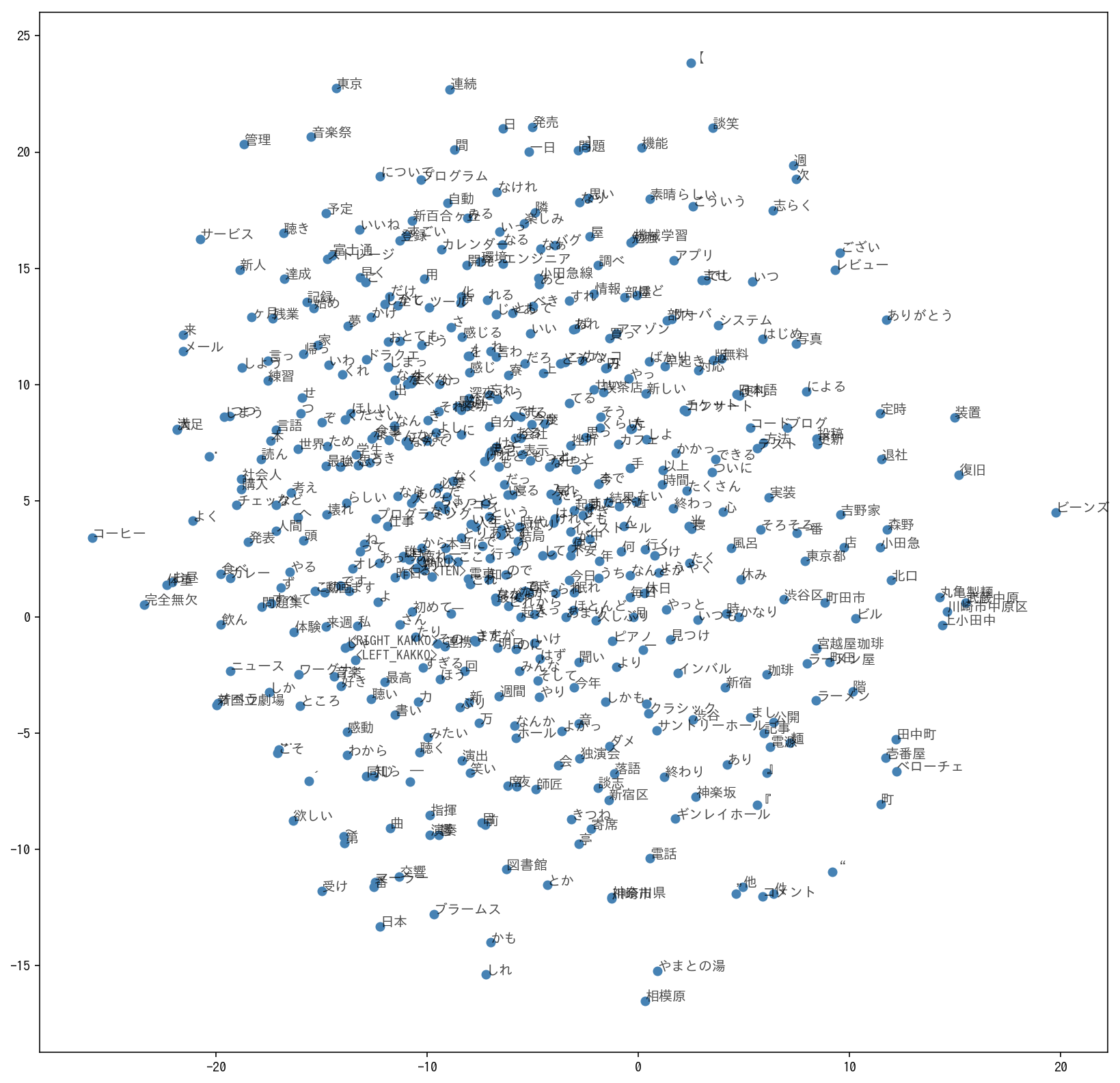
たとえば、落語という言葉に注目してみると、 周辺には寄席、談志、独演会など、落語関係の言葉がちゃんとあつまっている。