OpenAI Gym を試してみたメモです。
CartPole-v0 というゲームを動かしてみました。
OpenAI Gym
OpenAI Gym とは
OpenAI Gym is a toolkit for developing and comparing reinforcement learning algorithms.
OpenAI Gym は、強化学習アルゴリズムを開発し評価するためのツールキット。
- gym … python テスト環境ライブラリ.
- OpenAI Gym service … エージェントのパフォーマンスを評価するサービス。
ちょっとわかりにくいが、自分の解釈では、 いろんなゲームをプレイする環境が提供されていて、 自分の AI エージェントをつくってゲームをプレイして遊べるツール。
どんなゲーム(環境)があるの?
三目並べからシューティングゲーム、囲碁まである。詳しくは、以下。
Open AI Gym ライブラリのインストール
OpenAI Gym を pip でいれる。
pip install gym
以下のジャンルのゲームができるようになる。
- algorithmic
- toy_text
- classic_control
CartPole で遊ぼう
公式のチュートリアルで紹介されている CartPole というゲームを触ってみる。
CartPole 問題
CartPole 問題は、強化学習の古典的問題らしい。
棒(pole)が動く台車(cart)の上に立っている。 棒は倒れるので、台車を右か左に動かして倒れないようにする。 より長く棒を直立させることが目的。
以下は、ルールの Google 日本語翻訳。
ポールは、作動していないジョイントによって、摩擦のないトラックに沿って動くカートに取り付けられる。システムは、カートに+1 または-1 の力を加えることによって制御される。振り子が起立して、それが転倒するのを防ぐことが目標です。ポールが直立したままのタイムステップごとに+1 の報酬が与えられます。エピソードは、ポールが垂直から 15 度を超えると終了するか、またはカートが中心から 2.4 ユニット以上移動すると終了します。
- 1step の間に直立 h していれ報酬を 1 もらえる
- 右(+1) or 左(-1)の行動を選択できる
- 棒が 15 度傾くとゲームオーバー
- 台車が中心から一定距離(2.4unit???) とゲームオーバー
コードを調べる
公式ドキュメントに乗っているコードを見ていく。
import gym
env = gym.make('CartPole-v0')
for i_episode in range(20):
observation = env.reset()
for t in range(100):
env.render()
print(observation)
action = env.action_space.sample()
observation, reward, done, info = env.step(action)
if done:
print("Episode finished after {} timesteps".format(t+1))
break
まずは、gym というライブラリをインポートする。
gym.make(“環境名”) で動かす環境(env)を生成する。ここでは、CartPole-v0 を指定。
import gym
env = gym.make('CartPole-v0')
env の 3 つの主なメソッドは、
- reset() - 環境(environment)をリセットする。最初の 観測(observation) を返す。
- render() - 現在の環境の状態をレンダリングする。
- step(a) - 行動(action)を実行し、以下を返す(new observation, reward,
is done, info)
- new observation - 行動を実行したあとの観測
- reward - 報酬
- is done - ゲームが終了したら True, 続いているなら False
- info - 詳細情報
for 文で 20 エピソード分を実行する。
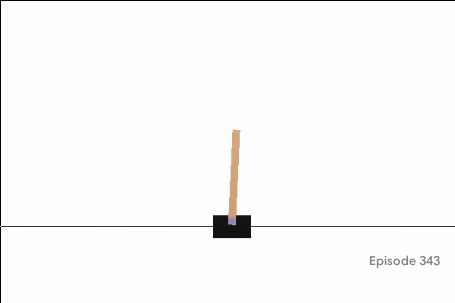
env.render()で以下のような図を表示する。
env.reset()を実行すると、以下の numpy 配列が帰ってくる。
# [position of cart, velocity of cart, angle of pole, rotation rate of pole]
array([-0.01717682, 0.00789496, 0.03295495, -0.0202679 ])
env.observation_space で、観測状態、env.action_space で、行動がそれぞれ帰ってくる。
Box は、n-次元の Box を、Discrete は固定された範囲の非負の数をそれぞれ表す。
print("observations:", env.observation_space)
print("actions:", env.action_space)
observations: Box(4,)
actions: Discrete(2)
CartPole-v0 では、observation は 4 次元の配列, action は 0 or 1 の数。
以下で、observation_space の上限、下限が分かる。
print(env.observation_space.high)
#> array([ 2.4 , inf, 0.20943951, inf])
print(env.observation_space.low)
#> array([-2.4 , -inf, -0.20943951, -inf])
以下で、action_space の数が分かる。
print(env.action_space.n)
#> 2
env.action_space.sample()で、action をランダムに選択できる。
env.action_space.sample()
#> 0
env.action_space.sample()
#> 1
env.action_space.sample()
#> 1
step()関数に action を渡すことで、action を実行できる。
done が True になるまで繰り返す。reward には、1.0 が入る。
結果を記録、アップロード
以下のように、wrappers.Monitor(env, ‘/tmp/cartpole-experiment-1’)を使うと、 実行結果を記録することができる。
import gym
from gym import wrappers
env = gym.make('CartPole-v0')
env = wrappers.Monitor(env, '/tmp/cartpole-experiment-1')
for i_episode in range(20):
observation = env.reset()
for t in range(100):
env.render()
print(observation)
action = env.action_space.sample()
observation, reward, done, info = env.step(action)
if done:
print("Episode finished after {} timesteps".format(t+1))
break
以下のような mp4 の動画と meta 情報の json がディレクトリに作成される。
$ ll /tmp/cartpole-experiment-1
合計 32K
-rw-rw-r-- 1 tsu-nera tsu-nera 817 6 月 9 15:59 openaigym.episode_batch.0.13181.stats.json
-rw-rw-r-- 1 tsu-nera tsu-nera 412 6 月 9 15:59 openaigym.manifest.0.13181.manifest.json
-rw-rw-r-- 1 tsu-nera tsu-nera 2.0K 6 月 9 15:58 openaigym.video.0.13181.video000000.meta.json
-rw-rw-r-- 1 tsu-nera tsu-nera 4.0K 6 月 9 15:58 openaigym.video.0.13181.video000000.mp4
-rw-rw-r-- 1 tsu-nera tsu-nera 2.0K 6 月 9 15:58 openaigym.video.0.13181.video000001.meta.json
-rw-rw-r-- 1 tsu-nera tsu-nera 3.9K 6 月 9 15:58 openaigym.video.0.13181.video000001.mp4
-rw-rw-r-- 1 tsu-nera tsu-nera 2.0K 6 月 9 15:58 openaigym.video.0.13181.video000008.meta.json
-rw-rw-r-- 1 tsu-nera tsu-nera 3.8K 6 月 9 15:58 openaigym.video.0.13181.video000008.mp4
以下のようなスクリプトを実行すると、OpenAI Gym に結果をアップロードできる。
import gym
gym.upload('/tmp/cartpole-experiment-1',api_key='<api key>')
api_key は、OpenAI Gym にログインすると得られる。
$ python carpole_upload.py
[2017-06-09 16:09:39,697] [CartPole-v0] Uploading 20 episodes of training data
[2017-06-09 16:09:48,712] [CartPole-v0] Uploading videos of 3 training episodes (9058 bytes)
[2017-06-09 16:09:49,232] [CartPole-v0] Creating evaluation object from /tmp/cartpole-experiment-1 with learning curve and training video
[2017-06-09 16:09:49,618]
****************************************************
You successfully uploaded your evaluation on CartPole-v0 to
OpenAI Gym! You can find it at:
https://gym.openai.com/evaluations/eval_7fz1aflRO6alkzRRfWhQ
****************************************************
gist にコードをあげて、URL を取得する。
評価ページにいき、gist を貼り付ける。以下のリンクが今回の評価ページ。
追記
長い間プログラムを動作させると、manifest.json ファイルが生成されなかった。 そういう場合は、念のため env.close()を終了時に呼び出すことで、manifest.jssn が生成されるようだ。 参考にしたコードはここ.