はじめに
とあるコンペに Keras で参加しているのだけれども、 ハイパーパラメータ、たとえば以下のようなパラメータ
- 隠れ層のニューロンの数
- ネットワークを何層にするか
- 学習率
をどう決めていたかというと、直感である。
これでは、いけないなと最近気づく。もっと早く気付けよ。
モデルに最適なハイパーパラメータの決め方を調べてみた。
“ディープラーニング ハイパーパラメータ"を検索
みんな困っているようで、事例はすぐにみつかった。 たとえば、この記事なんて、まさに自分のこと!!
これはテストデータの精度に対して、試行錯誤を繰り返しながら決めていくしかありません。
StackOverFlow でも、
asically it is just trial and error. Those are called hyperparameters and should be tuned on a validation set (split from your original data into train/validation/test).
Tuning just means trying different combinations of parameters and keep the one with the lowest loss value or better accuracy on the validation set, depending on the problem.
ようは、総当たりしろ!!!ということか??
3 つの手法:
また、別のページでは、もっと効率のよい方法が紹介されている。大きく分けて、3 つあるようだ。
- グリッドサーチ:
昔からある手法で、格子状の空間で最適なパラメータを探索する方法です。 格子の範囲を総当りするため、膨大な計算時間がかかるという課題があります。
- ランダムサーチ :
無作為にパラメータを抽出して探索します。 グリッドサーチよりも計算時間が短くて済むというメリットがあります。
- ベイズ最適化 (Bayesian Optimization) :
無作為にパラメータを抽出して探索します。 グリッドサーチよりも計算時間が短くて済むというメリットがあります。 ディープラーニングを含む機械学習の手法で、比較的良いハイパーパラメータを探索できることが知られています。
また、bengio 先生のおすすめレシピというのがある。
ハイパーパラメータはグリッドサーチするのではなく,ランダムサンプリングしたほうが性能が出る場合が多いよ
ベイズ最適化
ちょっとこのページは難しいが読み解くと、なにか得られそう。
- Deep Learning のハイパパラメータの調整 - もちもちしている
- 機械学習のためのベイズ最適化入門| Tech Book Zone Manatee
- » 機械学習のハイパーパラメータ探索 : ベイズ最適化の活用 TECHSCORE BLOG
ツール
scikit-learn には、GridSearchCV というものがあるらしい。いつか試そう。
hyperopt というツールもある。いつか試そう。
hyperopt の keras ラッパーもみつけた。いつか試そう。
調査結果
とりあえず、バカでも出来る全探索(グリッドサーチ)をする
目的
ここからが本題。
ニューラルネットワークのハイパーパラメータを調節したい。今回は簡単に以下の2つを調整。
- 隠れ層の数
- ニューロンの数
TensorBoard を Keras で使う
TensorBoard は、TensorFlow のログビューア。いい感じに可視化してくれる。
Keras で TensorBoard を使うには、Keras のコールバック機能を使う。 以下のように keras.collbacks.TensorBoard を利用する。
import keras
tbcb = keras.callbacks.TensorBoard(log_dir=log_filepath)
定義した変数を fit に渡す。
model.fit(trainX, trainY, epochs=30, batch_size=batch_size, validation_data=(validX, validY), callbacks=[tbcb])
これだけだ。簡単簡単。あとは log_filepath を指定して、tensorboard をコマンドラインから起動。port 6006 でアクセスできる。
$ tensorboard --logdir=[log_filepath]
参考: Keras から Tensorboard を使用する方法 - Qiita
複数のパラメータを追う
複数のパラメータをログするには、以下のように、log_dir に渡す文字列に変数を組み込む。
実例で示す。
import keras
from keras.models import Sequential
from keras.layers import Flatten, Dense, Dropout, BatchNormalization
from keras.optimizers import Nadam
batch_size=64
def get_model(num_layers, layer_size):
model = Sequential()
model.add(BatchNormalization(axis=1, input_shape=(256,3)))
model.add(Flatten())
for _ in range(num_layers):
model.add(Dense(layer_size, activation='relu'))
model.add(BatchNormalization(axis=1))
model.add(Dropout(0.2))
model.add(Dense(24, activation='softmax'))
model.compile(Nadam(), loss='categorical_crossentropy', metrics=['accuracy'])
return model
for num_layers in [2,3,4,5]:
for layer_size in [64,128,265,512,1024]:
log_string = 'logs/1/nl={},ls={}'.format(num_layers, layer_size)
tbcb = keras.callbacks.TensorBoard(log_dir=log_string)
model = get_model(num_layers, layer_size)
model.fit(trainX, trainY, epochs=30, batch_size=batch_size, validation_data=(validX, validY), callbacks=[tbcb])
こうすると、logs/1/配下に nl=?,ls=? というディレクトリがそれぞれできて、そのなかにログがたまる。
$ tree 1
1
├── nl=2,ls=1024
│ └── events.out.tfevents.1495116649.letsnote-ubuntu
├── nl=2,ls=128
│ └── events.out.tfevents.1495115992.letsnote-ubuntu
├── nl=2,ls=256
│ └── events.out.tfevents.1495116161.letsnote-ubuntu
├── nl=2,ls=512
│ └── events.out.tfevents.1495116351.letsnote-ubuntu
├── nl=2,ls=64
│ └── events.out.tfevents.1495115856.letsnote-ubuntu
├── nl=3,ls=1024
│ └── events.out.tfevents.1495118093.letsnote-ubuntu
├── nl=3,ls=128
│ └── events.out.tfevents.1495117340.letsnote-ubuntu
├── nl=3,ls=256
│ └── events.out.tfevents.1495117513.letsnote-ubuntu
├── nl=3,ls=512
│ └── events.out.tfevents.1495117727.letsnote-ubuntu
├── nl=3,ls=64
│ └── events.out.tfevents.1495117193.letsnote-ubuntu
├── nl=4,ls=1024
│ └── events.out.tfevents.1495119950.letsnote-ubuntu
├── nl=4,ls=128
│ └── events.out.tfevents.1495119010.letsnote-ubuntu
├── nl=4,ls=256
│ └── events.out.tfevents.1495119233.letsnote-ubuntu
├── nl=4,ls=512
│ └── events.out.tfevents.1495119509.letsnote-ubuntu
├── nl=4,ls=64
│ └── events.out.tfevents.1495118840.letsnote-ubuntu
├── nl=5,ls=1024
│ └── events.out.tfevents.1495122077.letsnote-ubuntu
├── nl=5,ls=128
│ └── events.out.tfevents.1495121077.letsnote-ubuntu
├── nl=5,ls=256
│ └── events.out.tfevents.1495121291.letsnote-ubuntu
├── nl=5,ls=512
│ └── events.out.tfevents.1495121586.letsnote-ubuntu
└── nl=5,ls=64
└── events.out.tfevents.1495120894.letsnote-ubuntu
これを tensorboard から見ると、accuracy, loss, valid loss, valid accuracy が見える。 以下の図は、valid accuracy.
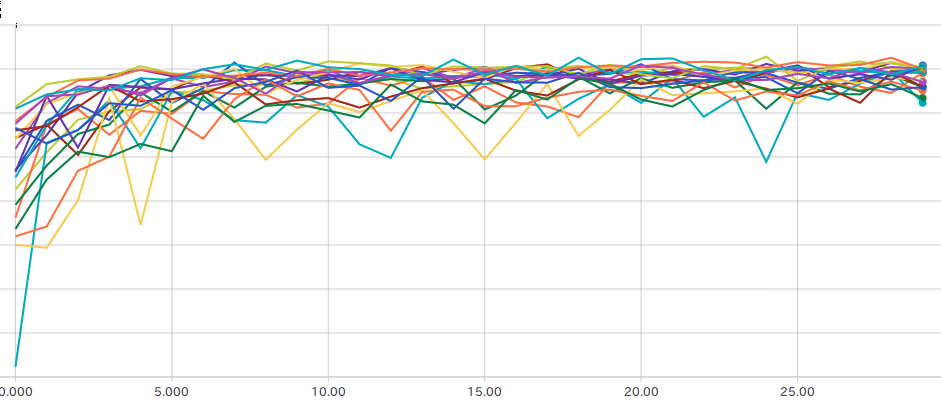
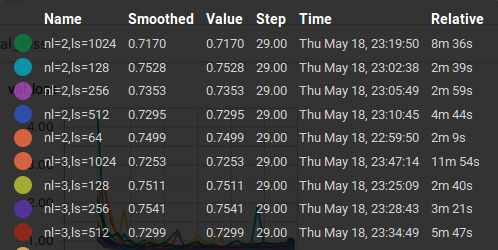
闇雲にパラメータを調べるよりもよっぽど効率がよい。